Anonymization vs Pseudonymization in LLM Workflows: Privacy, Utility, and Compliance

You have a dataset full of customer support logs, medical records, or internal emails. You want to feed it into your Large Language Model is an advanced artificial intelligence system capable of understanding and generating human-like text based on vast amounts of training data to build something useful. But there’s a catch: that data contains names, addresses, and other sensitive details. If you send raw data to an AI model, you risk exposing private information, violating regulations like the General Data Protection Regulation is a comprehensive European Union law designed to protect the privacy and personal data of individuals within the EU, and potentially losing customer trust. So, what do you do? Do you scrub everything until the data is useless for analysis, or do you mask it just enough to keep it safe while still being usable?
This is where the choice between Anonymization is the irreversible process of removing all personally identifiable information from data so that individuals cannot be identified and Pseudonymization is a reversible data protection technique that replaces identifying fields with artificial labels or codes while maintaining the ability to re-identify individuals with additional information comes into play. These aren’t just buzzwords; they are two fundamentally different approaches to handling data privacy in AI workflows. One offers total, irreversible privacy but kills data utility. The other keeps the data useful for business logic but requires heavy security lifting. Choosing the wrong one can lead to compliance failures or wasted engineering effort.
The Core Difference: Reversibility and Risk
At its heart, the difference lies in whether you can go back. Anonymization is a one-way street. Once you anonymize data, you should never be able to link it back to a specific person. It’s like shredding a document and burning the pieces. Under GDPR, properly anonymized data is no longer considered personal data. This means if your anonymized database gets breached, you generally don’t have to notify regulators because no personal information was exposed. The risk is low, but the trade-off is high: you lose the ability to connect that data point to a user later.
Pseudonymization, on the other hand, is like putting a nickname on a file. You replace "John Doe" with "User_123" or encrypt his email address using a key. The data looks safe, but if someone has the key (or the mapping table), they can reverse the process and find out who User_123 really is. Because this reversal is possible, GDPR still treats pseudonymized data as personal data. If a hacker steals your pseudonymized dataset and also manages to get your encryption keys, you’re looking at a major breach notification requirement. However, the benefit is clear: you can still analyze trends, track customer journeys, and perform longitudinal studies without exposing raw identities during daily operations.
| Feature | Anonymization | Pseudonymization |
|---|---|---|
| Reversibility | Irreversible (One-way) | Reversible (With Key/Mapping) |
| GDPR Status | Not Personal Data | Personal Data |
| Breach Notification | Usually Not Required | Required |
| Data Utility | Low (Loss of Context) | High (Retains Structure) |
| Security Burden | Low | High (Key Management) |
| Best For | Public Sharing, Compliance | Internal Analytics, Testing |
Technical Implementation in LLM Pipelines
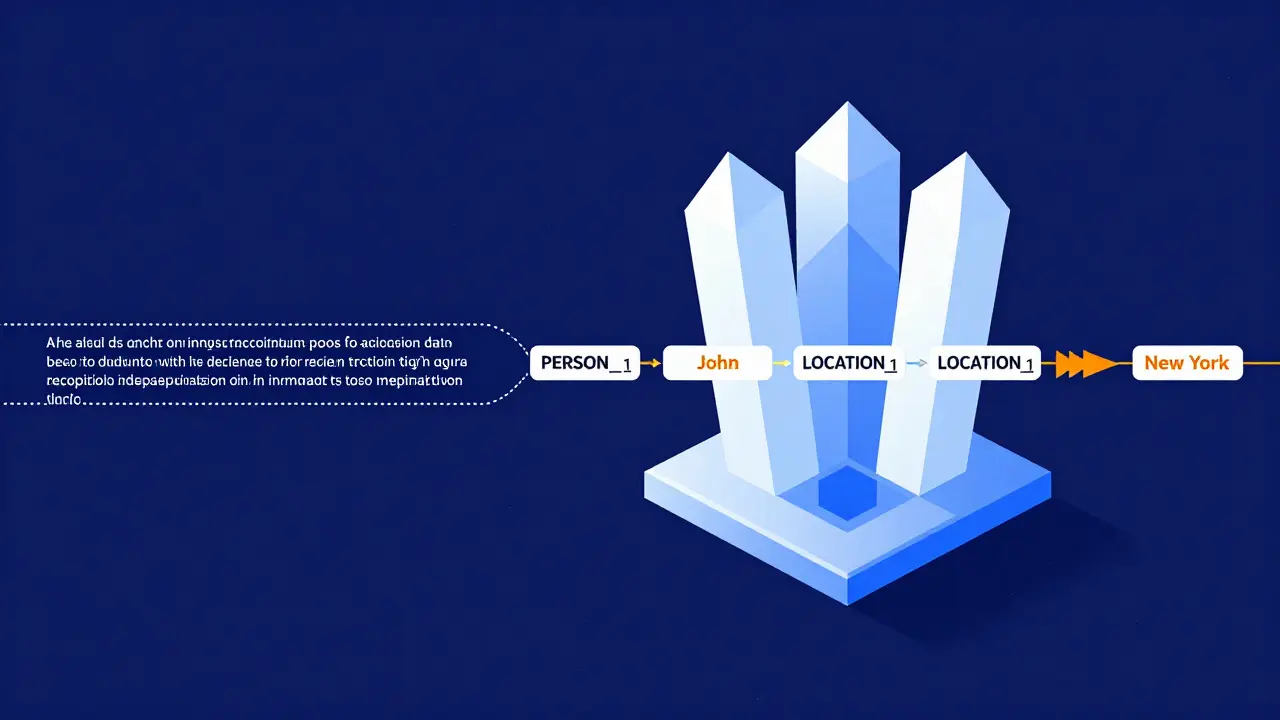
Implementing these techniques isn't just about deleting words. In the context of Large Language Models, you need methods that preserve the semantic meaning of the text so the AI can still learn from it. For pseudonymization, teams often use Named Entity Recognition (NER) models. A popular choice is the XLM-RoBERTa is a multilingual transformer-based language model developed by Facebook AI, known for its strong performance in natural language processing tasks. This model identifies entities like names, locations, and organizations and replaces them with structured tags. For example, "New York" becomes "LOCATION_1" and "John Smith" becomes "PERSON_1". This keeps the sentence structure intact, which is crucial for the LLM to understand grammar and context.
Anonymization takes a more aggressive approach. Techniques include generalization, where specific ages (e.g., 34) are replaced with ranges (e.g., 30-40), and data masking using libraries like Faker is a Python library used to generate fake data such as names, addresses, and phone numbers for testing and development purposes. Faker generates realistic but completely fictional data. So, instead of removing a name entirely, you might replace it with "Alice Johnson". This maintains the statistical distribution of the data, which helps prevent the LLM from noticing anomalies in the dataset. Another method is tokenization, where sensitive strings are replaced with unique, non-reversible tokens.
Impact on Model Performance and Quality
A common fear among developers is that scrubbing data will make their AI dumb. Will the model fail to understand the context if all the names are gone? Recent research suggests the impact is surprisingly minimal. A study published in the ACL Anthology's PrivateNLP workshop in 2025 tested three strategies: simple masking, contextual anonymization (adding descriptions to masked entities), and pseudonymization. They found that response quality dropped by only about 1 point on a 10-point scale across all methods, while entity privacy preservation hit between 97% and 99%.
However, the optimal strategy depends heavily on the model architecture. For instance, when testing with the Llama 3.3 is a large open-source language model developed by Meta, known for its efficiency and performance in various natural language tasks 70-billion-parameter model, straightforward anonymization worked best, achieving an inference score of 0.83. Interestingly, adding context to the masked entities actually hurt performance, dropping the score to 0.46. This suggests that complex descriptions can confuse some models, making them try to reconstruct the original entity rather than focus on the task. Conversely, GPT-4o is a multimodal large language model developed by OpenAI, optimized for speed and accuracy across text, image, and audio inputs benefited from added context, showing that different models interpret masked data differently. This highlights a critical lesson: there is no universal "best" technique. You must test your specific pipeline.
When to Use Which Approach
Your decision should be driven by your business goals and regulatory environment. If you are building a fraud detection system or a customer service bot that needs to reference past interactions, pseudonymization is likely your friend. You need to link today’s query to yesterday’s complaint without exposing the raw data to every engineer working on the model. Pseudonymization allows for this longitudinal tracking. It is also ideal for sharing data with trusted partners or vendors who need to run analytics but shouldn’t see individual identities.
On the flip side, choose anonymization when you plan to publish datasets publicly, share data with untrusted third parties, or when regulatory compliance is your absolute top priority. If you are conducting broad market research or training a generic model that doesn’t need to know who the users are, anonymization provides the highest security level with the lowest ongoing maintenance burden. You don’t need to worry about securing encryption keys or managing access controls for a mapping table.
Security and Governance Requirements
Don’t underestimate the operational cost of pseudonymization. Because it is reversible, it demands robust security infrastructure. You must implement strict access management to control who can view the mapping keys. You need audit trails to track who accessed the pseudonymized data and when. Encryption standards must be up-to-date, and key rotation policies should be enforced. If you fail here, you are holding a liability bomb. Anonymization, once done correctly, frees you from much of this burden. You can manage it under internal ethics guidelines rather than heavy regulatory mandates. However, remember that "correctly" is the keyword. If your anonymization is weak and re-identification is possible through linkage attacks, you are still liable under GDPR.
Practical Recommendations for Teams
If you are starting fresh, begin by auditing your data. Identify direct identifiers (names, emails, IP addresses) and indirect identifiers (job titles, rare combinations of demographics). Research shows that removing direct identifiers yields a significant privacy boost with minimal utility loss compared to removing indirect ones. Start with pseudonymization for internal tools to maintain functionality. As you move toward production or public-facing features, layer in anonymization techniques. Use automated NER tools to handle bulk processing, but always have a human-in-the-loop review for edge cases. Finally, continuously monitor your model’s output. Even with perfect input sanitization, LLMs can sometimes memorize and leak patterns. Regular audits are essential to ensure your privacy measures hold up against evolving inference attacks.
Is pseudonymized data considered personal data under GDPR?
Yes. Because pseudonymization is reversible with the use of additional information (like a key), the data remains linked to an individual. Therefore, GDPR treats it as personal data, requiring full compliance measures including breach notifications if compromised.
Does anonymizing data reduce the effectiveness of my LLM?
Minimal impact is observed. Studies show a reduction of approximately 1 point on a 10-point quality scale. Simple anonymization often performs better than complex contextual masking for models like Llama 3.3, while GPT-4o may benefit from contextual clues. Always test with your specific model.
What is the best tool for pseudonymizing text in Python?
Libraries utilizing NER models like XLM-RoBERTa are highly effective. Additionally, specialized libraries designed for privacy-preserving data transformation can help replace entities with consistent pseudonyms while maintaining syntactic integrity.
Can I switch from pseudonymization to anonymization later?
Technically yes, but it is difficult. Once data is pseudonymized, you retain the mapping. To anonymize it, you must destroy the mapping and apply irreversible transformations to the data itself. This process is complex and risks leaving residual traces that could allow re-identification.
Why did adding context hurt Llama 3.3 performance in tests?
Research indicates that adding descriptive context to masked entities can cause some models to attempt reconstructing the original entity rather than focusing on the task. This distraction reduces inference scores, suggesting simpler masking is often more effective for certain architectures.
- May, 19 2026
- Collin Pace
- 0
- Permalink
- Tags:
- LLM privacy
- data anonymization
- pseudonymization GDPR
- AI data protection
- machine learning security
Written by Collin Pace
View all posts by: Collin Pace