Privacy Impact Assessments for Large Language Model Projects: A Complete Guide

Building a generative AI tool is exciting, but it can quickly turn into a legal nightmare if you ignore how the model handles personal data. Traditional privacy checks don't work here because Privacy Impact Assessments (PIAs) for LLMs have to deal with a unique problem: the model doesn't just store data in a table; it "absorbs" it into billions of parameters. When a model starts regurgitating customer social security numbers or private emails, a standard spreadsheet of data flows won't save you from a massive fine.
Why standard PIAs fail with generative AI
If you've done a privacy assessment before, you're used to mapping out where data comes from, where it lives, and who sees it. With a Large Language Model (LLM), that linear path disappears. The central issue is Privacy Impact Assessments must now account for probabilistic outputs. Unlike a database, an LLM can "memorize" a piece of sensitive info during training and spit it out months later to a completely different user.
According to the European Data Protection Board (EDPB), LLM-specific assessments require about 47% more criteria than standard ones. You aren't just looking at the "input" and "output"; you're looking at data provenance. For instance, many models are trained on thousands of domains-sometimes over 4,800-via indiscriminate scraping. This creates a huge risk where personal data is treated as "free raw material," which often clashes with GDPR (General Data Protection Regulation) requirements for lawful processing.
The 6-phase framework for LLM privacy
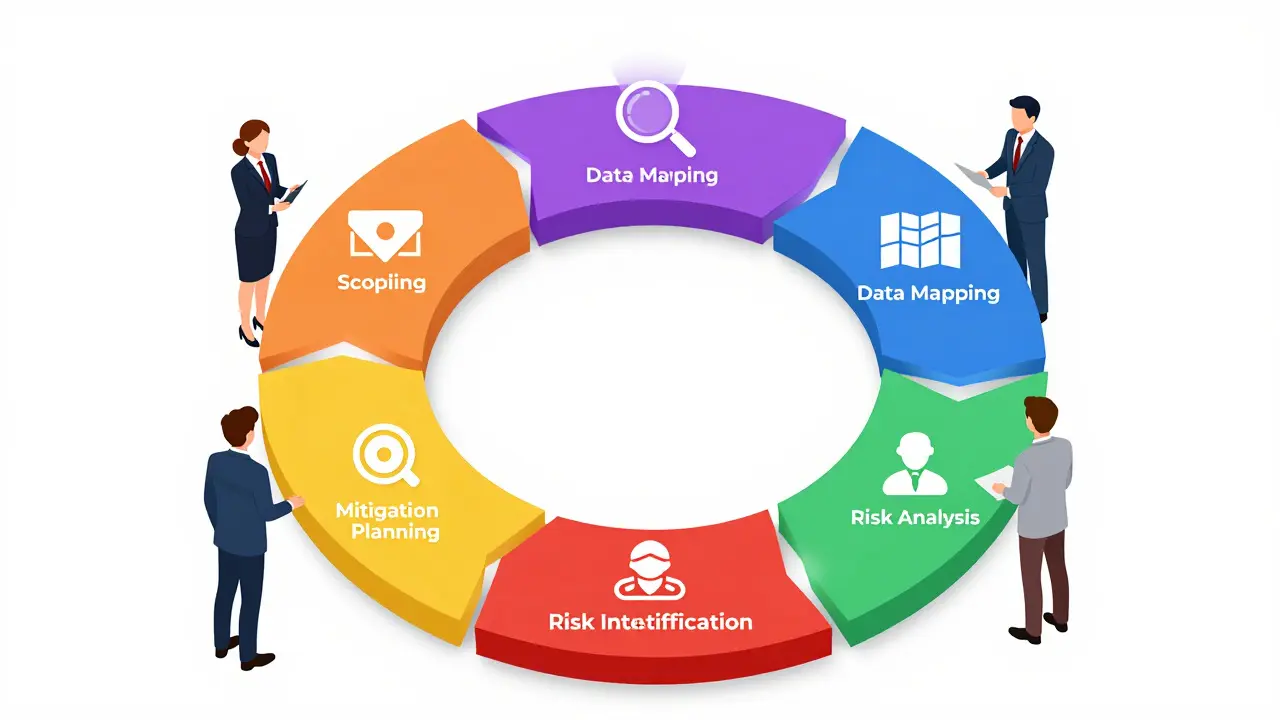
To actually get this right, you can't just wing it. The EDPB suggests a structured approach that integrates directly into your development lifecycle. It's not a one-time checkbox; it's a continuous loop.
- Scoping: Define exactly what the LLM does. Is it a customer service bot? A code generator? The risk profile of a medical bot is vastly different from a marketing tool.
- Data Mapping: Identify every piece of data used for training, fine-tuning, and the RAG (Retrieval-Augmented Generation) knowledge base.
- Risk Identification: Look for "regurgitation" risks. Can a clever prompt trick the model into revealing PII (Personally Identifiable Information)?
- Risk Analysis: Determine the severity. A leaked email address is bad; a leaked health record is a catastrophic compliance failure.
- Mitigation Planning: Decide on your defenses. This might include using Differential Privacy or automated redaction tools.
- Documentation: Create a living record of these decisions. This is your "get out of jail free" card during a regulatory audit.
Comparing Traditional PIAs vs. LLM PIAs
The shift in focus is massive. While the old way focused on the storage of data, the new way focuses on the behavior of the model.
| Feature | Traditional PIA | LLM-Specific PIA |
|---|---|---|
| Primary Focus | Data flows and storage | Model memorization and output risks |
| Data Deletion | Simple (Delete row from DB) | Complex (Parameter entanglement) |
| Risk Vector | Unauthorized access/leaks | Prompt injection and regurgitation |
| Effort Required | Moderate | High (3-5x more assessment hours) |
Critical risks you can't ignore
When conducting your assessment, keep an eye on three specific technical danger zones. First is Model Memorization. This is where the model effectively "hard-codes" a piece of training data. If your training set included private contracts, the model might output those exact clauses to a user.
Second is the RAG Pipeline. Many companies use Retrieval-Augmented Generation to give models access to internal company docs. If your access controls aren't airtight, a junior employee could ask the bot about the CEO's salary, and the RAG system will happily fetch that document and summarize it.
Finally, there's the Interpretation Gap. Research from AIM Councils shows that about 32% of AI-generated policy summaries are inaccurate. If you rely on your own LLM to explain your privacy policy to users, you might be giving false compliance assurances, which is a fast track to a regulatory fine.
Building your assessment team
You cannot expect a single person to handle this. A common mistake is handing the whole project to the legal team or the engineering team. Legal doesn't understand how weights and biases work, and engineers often view privacy as a "hindrance" to performance.
The most successful implementations use a cross-functional squad. The EDPB recommends a minimum team consisting of:
- One Data Protection Officer (DPO): To ensure the project aligns with laws like the EU AI Act or CCPA.
- Two AI Engineers: To analyze the training pipeline and implement technical guards.
- One Legal Compliance Specialist: To handle the specific contractual obligations of data providers.
Don't be surprised if this takes a while. One data governance specialist shared on Reddit that their LLM PIA took 14 weeks to complete, but it saved them from a potential $2.3M GDPR fine after they discovered the model was memorizing customer social security numbers.

Pro Tips for Mitigation
Once you've identified the risks, how do you actually fix them? Manual review is too slow. IBM's Adaptive PII Mitigation framework, for example, uses AI to fight AI, achieving a 0.95 F1 score in detecting passports-far better than older tools like Presidio.
If you're in a highly regulated field, look into Privacy-Enhancing Technologies (PETs). Instead of just scrubbing a dataset, use differential privacy to add mathematical noise to the data. This allows the model to learn the patterns without remembering the individuals. In healthcare, systems like Oracle Health's RedactOR have shown that you can achieve nearly 97% accuracy in identifying protected health information, making the model much safer for clinical use.
Is a PIA mandatory for every LLM project?
Under the EU AI Act, high-risk AI systems are required to undergo mandatory PIAs. Even if your project isn't legally "high-risk," failing to conduct one leaves you vulnerable to GDPR penalties if personal data is leaked through model outputs.
How do I handle the "Right to be Forgotten" in an LLM?
This is one of the hardest parts of an LLM PIA. Because data is entangled in model parameters, you can't just "delete" a person. Mitigation strategies include retraining the model without the data (expensive) or using robust output filters to block the model from mentioning that specific individual.
How long does a typical LLM PIA take to complete?
It varies, but data from IPC NSW suggests an average of 220 staff hours per assessment. Complex projects can take several months due to the need for deep technical auditing of the training sets.
Can I use an AI tool to conduct my Privacy Impact Assessment?
Yes, and it's becoming common. AI-powered assessment tools can reduce manual review time by up to 72%, but they should be used to assist a human expert, not replace them, especially when interpreting complex legal requirements.
What is the difference between PII and sensitive data in an LLM context?
PII (Personally Identifiable Information) is any data that can identify a person, like an email. Sensitive data includes "special categories" under GDPR, such as health records, political opinions, or biometric data. LLM PIAs must apply stricter controls and higher risk ratings to sensitive data.
Next Steps and Troubleshooting
If you're just starting, don't try to map everything at once. Start with a pilot workshop to get your engineers and lawyers in the same room. If you find that your team is overwhelmed by the complexity, focus on the "high-leakage" areas first: the training data collection and the user-facing prompt interface.
For those in financial services or healthcare, prioritize HIPAA or CCPA compliance modules. If you're deploying a model across borders, be careful-what's compliant in the US might be illegal in the EU. Your PIA needs to include a specific section on cross-border data transfer risks to avoid conflicting regulatory requirements.
- Apr, 4 2026
- Collin Pace
- 9
- Permalink
- Tags:
- Privacy Impact Assessments
- Large Language Model
- GDPR compliance
- AI privacy risks
- data protection
Written by Collin Pace
View all posts by: Collin Pace