Representation Learning in Generative AI: How Embeddings Capture Meaning

When you ask a generative AI model to write a poem about a rainy day in Madison, it doesn’t remember the weather reports or poetry books you’ve read. Instead, it works with embeddings-numerical vectors that carry the meaning of words, sentences, and even entire ideas. These aren’t just numbers. They’re compressed, learned representations of meaning, shaped by massive amounts of data and neural networks. Understanding how embeddings work is the key to understanding how generative AI actually thinks.
What Embeddings Really Are
Think of embeddings as digital fingerprints for meaning. A single word like ‘bank’ doesn’t have one fixed meaning-it could mean a riverbank, a financial institution, or the action of tilting an airplane. An embedding turns each usage into a unique vector in a high-dimensional space. Words with similar meanings end up close together. ‘Riverbank’ and ‘shoreline’ might be neighbors. ‘Bank’ and ‘credit union’ might be nearby too. The distance between vectors reflects semantic distance, not just word overlap.
This isn’t magic. It’s math. Models like BERT, Sentence-BERT, or CLIP take text, images, or audio and map them into spaces with hundreds or thousands of dimensions. Each dimension isn’t labeled-it doesn’t mean ‘emotion’ or ‘size.’ But together, the pattern of values across all dimensions captures context, tone, and intent. A 384-dimensional vector from Sentence-BERT can represent an entire sentence in a way that lets machines compare its meaning to another sentence, even if they use completely different words.
How Generative Models Learn Embeddings
Generative AI doesn’t start with pre-defined meanings. It learns them. Models like Variational Autoencoders (VAEs) and Generative Adversarial Networks (GANs) are trained to reconstruct data. A VAE takes an image of a cat, compresses it into a latent vector (its embedding), then tries to rebuild the image from that vector. If the reconstruction is poor, the model adjusts its internal parameters. Over millions of examples, it learns which patterns in the data are important enough to preserve in the embedding.
That latent space-the space where all those vectors live-is where the real magic happens. It’s not random. It’s structured. Similar cats cluster together. Different breeds form separate neighborhoods. Even abstract concepts like ‘joyful’ or ‘mysterious’ show up as directions in the space. That’s why you can do things like ‘cat + happy = puppy’ in some models: the vector math aligns with learned semantic relationships.
Modern transformer-based models like those behind ChatGPT or Claude take this further. They don’t just encode words-they encode context. The embedding for ‘Apple’ in ‘I ate an Apple’ is different from ‘Apple released a new iPhone.’ The model learns these differences automatically, without being told.
Why Embeddings Power Retrieval-Augmented Generation (RAG)
Most generative AI systems today don’t just guess answers-they look things up. That’s Retrieval-Augmented Generation (RAG). Here’s how it works: when you ask a question, the system converts your query into an embedding. Then it searches a vector database-like Pinecone or Weaviate-for the most similar embeddings stored from documents, research papers, or manuals. The top matches are fed into the language model, which then generates a response grounded in real data.
This system only works if the same embedding model is used everywhere. If the documents were embedded using one model and your query uses another, the search fails. The vectors won’t align. That’s why experts recommend sticking with proven models like sentence-transformers/all-MiniLM-L6-v2 a lightweight, high-performance embedding model trained on diverse text corpora for semantic similarity tasks. Switching models mid-project is like changing the language of your database. The system breaks.
And it’s not just about accuracy. Consistency matters in healthcare, finance, or legal systems. If a model retrieves different documents on Tuesday than on Monday for the same query, someone could make a bad decision. Embeddings must be stable. Reproducible. That’s why you don’t fine-tune them on the fly.
Embeddings Reveal Hidden Biases and Origins
Embeddings don’t lie-but they do remember. Research from the National Center for Biotechnology Information shows that even two datasets of real cat images, one from LSUN and one from Cats&Dogs, create separate clusters in embedding space. Not because the cats are different, but because the photos were taken with different cameras, lighting, or angles. The model learned those subtle patterns and encoded them as part of the representation.
This is a problem. And it’s also a feature. These differences are called generative DNA the unique, inherent signature left by a model’s training data and architecture, detectable in its output embeddings. Every generative model leaves a fingerprint. A model trained on Reddit data will embed text differently than one trained on academic journals. Even the same model, given different prompts, produces subtly different embeddings. That’s not a bug. It’s a traceable signature.
That’s why researchers can now detect AI-generated images or text without special detectors. Just look at the embedding space. Real and fake data naturally separate. The noise, the texture, the statistical quirks-all get baked into the vectors. You don’t need a new algorithm. You just need to look at the numbers.
From Manual Features to Learned Representations
Before embeddings, feature engineering was a manual art. Data scientists spent weeks crafting variables: ‘number of words per sentence,’ ‘average sentiment score,’ ‘presence of exclamation marks.’ It was painstaking, domain-specific, and limited. Embeddings changed that. Now, the neural network learns the best features itself.
Think of it as automated feature discovery. A model looking at medical records doesn’t need a human to tell it that ‘elevated CRP levels + fever’ might indicate infection. It learns that pattern from millions of cases. The embedding captures it as a direction in space. This is why deep learning outperforms older methods: it doesn’t rely on human intuition. It finds patterns we didn’t know to look for.
That’s also why embeddings are so powerful across modalities. The same technique works for text, images, audio, even DNA sequences. A text embedding and an audio embedding can live in the same space. You can compare a spoken question to a written transcript. You can search for a song by describing it in words. That’s because embeddings don’t care about the source-they care about the meaning.
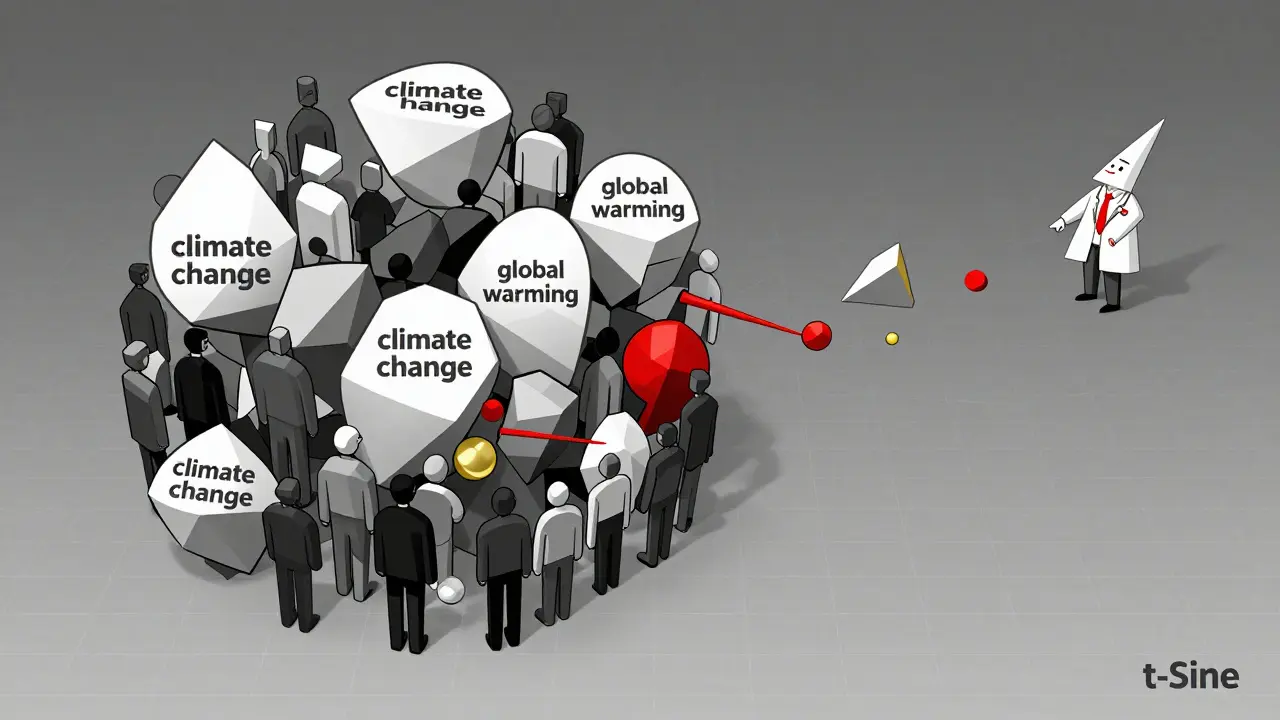
Visualizing Meaning: What Embeddings Look Like
Embeddings are high-dimensional. You can’t see 768 dimensions. But you can reduce them. Tools like t-SNE and UMAP take those vectors and flatten them into 2D or 3D plots. Suddenly, you can see clusters. You see how ‘climate change’ and ‘global warming’ group together. You notice outliers-maybe a document that’s oddly placed, hinting at bias or error.
These visualizations aren’t just pretty pictures. They’re diagnostic tools. If your customer support chatbot keeps pulling up the wrong answers, you can plot the embeddings of your training data and your queries. Are they in the same neighborhood? If not, your embedding model isn’t aligned with your use case. You can fix it.
Many teams use this for quality control. Before deploying a system, they run embeddings through UMAP. If the clusters are messy, they know something’s off. Maybe the data was poorly labeled. Or maybe the model was trained on outdated sources. Embeddings make hidden problems visible.
The Limits and Risks of Embeddings
Embeddings aren’t perfect. They’re only as good as the data they’re trained on. If your training data is biased, your embeddings will be too. If your data is sparse, the vectors will be noisy. If your model is too small, it can’t capture complexity.
And there’s another risk: over-reliance. Some teams treat embeddings as black boxes. They assume the model knows what it’s doing. But embeddings don’t understand-they correlate. They can pick up accidental patterns: ‘doctors’ are closer to ‘men’ in some embeddings because of historical data. That’s not truth. That’s noise.
That’s why you need human oversight. Embeddings help you scale understanding. But they don’t replace judgment. Always check: are the results making sense? Are the clusters logical? Are the retrieved documents actually relevant?
What Comes Next
Embeddings are evolving. New models are learning to embed not just static data, but time-series, multi-modal interactions, and even emotional tone. Some researchers are building embeddings that change based on user context-your query about ‘diabetes’ might trigger a different embedding if you’re a patient vs. a doctor.
But the core idea stays the same: meaning is measurable. And if you can measure it, you can manipulate it, search it, and generate from it. That’s why embeddings are the backbone of generative AI. Not because they’re flashy. But because they turn the messy, chaotic world of human language and perception into something machines can reason with.
How do embeddings differ from traditional word embeddings like Word2Vec?
Traditional word embeddings like Word2Vec represent individual words as vectors, often missing context. For example, the word ‘bank’ gets one vector regardless of whether it’s about money or rivers. Modern embeddings, especially from transformer models like BERT or Sentence-BERT, generate context-sensitive vectors. The same word gets different representations based on its surrounding text. This allows for much richer, more accurate semantic understanding, especially for full sentences or paragraphs.
Why do embedding models need to be consistent across a system?
Embeddings are only meaningful when compared within the same space. If your documents are embedded with one model and your queries use another, the vectors won’t align. Even small differences in training data or architecture can shift the entire space. This leads to poor retrieval accuracy in RAG systems. Using the same model-like sentence-transformers/all-MiniLM-L6-v2-ensures all data lives in the same semantic space, making search reliable and reproducible.
Can embeddings be used for non-text data like images or audio?
Absolutely. Models like CLIP, ViT, and Whisper convert images and audio into embeddings using the same principles as text. A picture of a sunset and the phrase ‘golden hour’ can end up with similar vectors. This enables cross-modal search-like finding videos by typing a description, or identifying songs from a hummed melody. The underlying math is the same: map complex input into a space where similarity reflects meaning.
Are embeddings the same as AI-generated content?
No. Embeddings are the internal representations the AI uses to understand data. The generated content-like a paragraph of text or an image-is the output. Think of embeddings as the brain’s memory of meaning, and generated content as the spoken word. You can’t see the embedding when you read a chatbot’s reply. But the embedding is what made that reply accurate and relevant.
How do you choose the right embedding model for your project?
Start with your data type and use case. For text, sentence-transformers/all-MiniLM-L6-v2 is a strong default-fast, accurate, and widely used. For multilingual data, try paraphrase-multilingual-MiniLM-L12-v2. For images, use CLIP. Always test performance on your own data. Don’t assume bigger is better. A smaller, well-tuned model often outperforms a large, generic one. And never switch models mid-project-consistency beats novelty.
- Mar, 11 2026
- Collin Pace
- 6
- Permalink
Written by Collin Pace
View all posts by: Collin Pace