Retrieval-Augmented Generation (RAG): How to Ground AI in Verified Sources

Imagine asking your company's internal AI assistant about the latest travel policy. Instead of giving you a confident but completely made-up answer from its training data, it pulls up the actual PDF from last week's update and cites page 4. That shift-from guessing based on static memory to answering with live proof-is exactly what Retrieval-Augmented Generation is a machine learning framework that enables large language models to retrieve and incorporate information from external data sources before generating responses. In the industry, we call this RAG.
As of mid-2026, RAG has moved from experimental research to the backbone of enterprise AI. It solves the biggest problem plaguing generative AI: hallucinations. When Large Language Models (LLMs) rely solely on their pre-trained weights, they are essentially predicting the next likely word based on patterns seen during training, not facts. This leads to plausible-sounding nonsense. RAG fixes this by connecting the model to a dynamic knowledge base, reducing hallucination rates by 47% to 63%, according to MIT’s 2023 benchmark study.
How RAG Works: The Four-Stage Pipeline
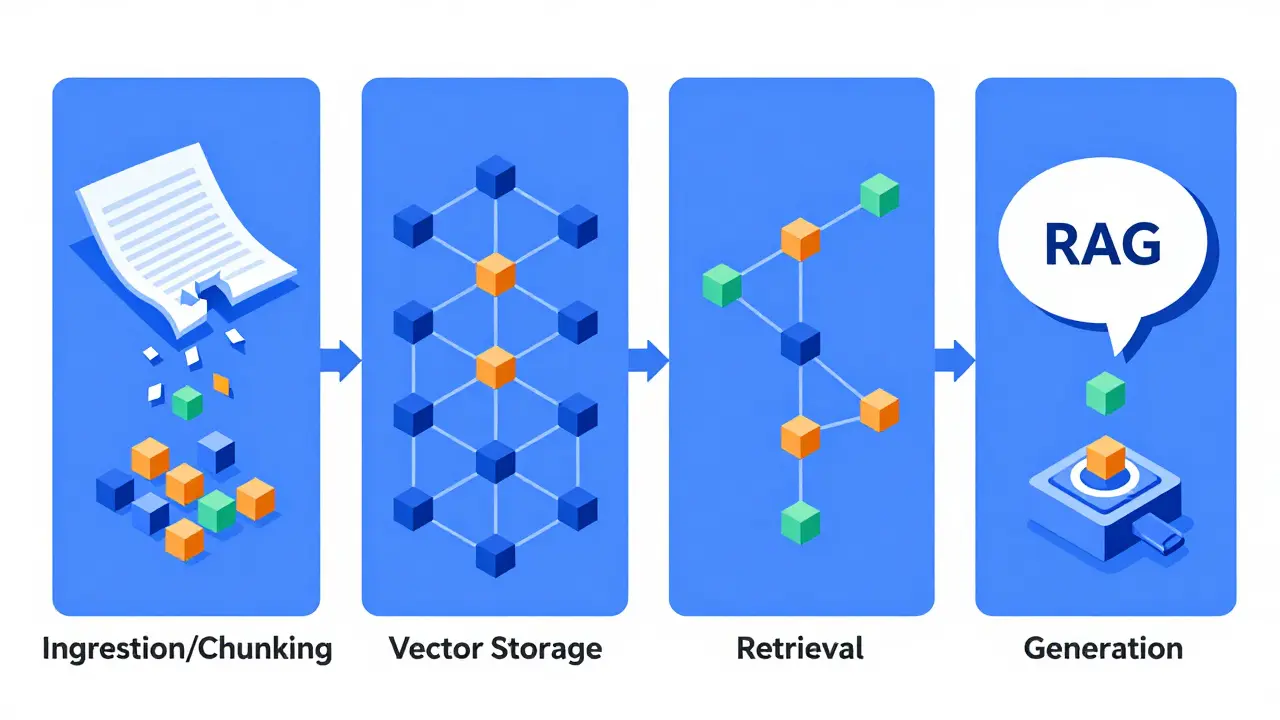
To understand why RAG is so effective, you need to look under the hood. It isn't magic; it's a structured pipeline consisting of four distinct stages: Ingestion, Retrieval, Augmentation, and Generation.
- Ingestion: Your raw documents-PDFs, Word docs, database entries-are broken down into smaller chunks. Typically, these chunks range from 256 to 512 tokens. Why? Because if you feed an entire book into the system, the signal gets lost in the noise. These chunks are then converted into vector embeddings using models like OpenAI's text-embedding-3-large or Cohere's Embed Multilingual v3.0. These embeddings create mathematical representations (usually 1024-dimensional vectors) that capture semantic meaning, not just keywords.
- Storage: These vectors are stored in specialized vector databases such as Pinecone, Weaviate, or AWS OpenSearch. As of Q2 2025, Pinecone clusters can handle up to 1.2 billion vectors, ensuring scalability for massive enterprise datasets.
- Retrieval: When a user asks a question, the system converts that query into a vector too. It then searches the database for the most similar vectors using algorithms like HNSW (Hierarchical Navigable Small World). A cosine similarity threshold of ≥0.78 is often used to ensure relevance. Hybrid search approaches, which combine keyword matching with vector similarity, have been shown to improve recall by 32%, per Google Cloud’s 2024 whitepaper.
- Augmentation & Generation: The top 3-5 retrieved chunks are combined with the user's original question into a prompt template. This enriched prompt is sent to the LLM (like Anthropic's Claude 3.5 or Meta's Llama 3.1), which generates a response grounded strictly in the provided context.
RAG vs. Fine-Tuning: Choosing the Right Path
A common question I hear from developers is, "Why not just fine-tune the model?" Fine-tuning involves retraining the neural network weights on new data. While powerful, it is expensive and rigid. According to Hugging Face’s January 2025 report, retraining a model can cost over $50,000 per iteration. In contrast, RAG achieves comparable accuracy improvements at just 5-8% of that cost, based on IBM’s March 2025 benchmark study.
| Feature | Retrieval-Augmented Generation (RAG) | Fine-Tuning |
|---|---|---|
| Cost Efficiency | High (5-8% of fine-tuning costs) | Low ($50k+ per iteration) |
| Data Freshness | Real-time updates possible | Static until next retrain |
| Accuracy in Dynamic Fields | 92.7% (e.g., financial regulations) | 78.4% (due to outdated models) |
| Complex Reasoning | Lower (14.2-point gap on multi-hop tasks) | Higher (deep structural understanding) |
| Hallucination Risk | Reduced by 47-63% | Variable, depends on training data quality |
Fine-tuning shines when you need deep domain adaptation, such as integrating specific medical terminology where Mayo Clinic trials showed a 19.3% accuracy boost. However, for scenarios requiring frequent updates-like quarterly financial regulations or changing HR policies-RAG is superior. It keeps the knowledge current without touching the model weights.
Implementation Challenges and Pitfalls
While RAG is powerful, it is not plug-and-play. Implementing it requires navigating several technical hurdles. One major issue is "retrieval drift," cited in 23% of negative reviews on Capterra. This happens when slightly altered queries retrieve irrelevant documents because the vector similarity score was technically high but semantically weak. Another common complaint is "context overload," noted in 17% of GitHub issues for LangChain. If you retrieve too many chunks, the LLM gets confused by contradictory information, leading to poor outputs.
Latency is another concern. A developer on Reddit’s r/MachineLearning reported that after implementing RAG with LangChain and ChromaDB, their customer support bot’s accuracy jumped from 67% to 89%, but latency increased from 1.2 seconds to 3.8 seconds per query. For real-time applications, this delay can be unacceptable. To mitigate this, teams are optimizing chunking strategies and using reranking techniques. Cohere’s Rerank v3.0, for instance, boosts precision by 34% by filtering out less relevant results before they reach the LLM.
There is also the risk of "retrieval poisoning," identified by Forrester in early 2025. Adversaries can manipulate knowledge bases to inject misleading information, which the RAG system then retrieves and presents as fact. Carnegie Mellon University’s Security Lab demonstrated success rates of 63% in penetration tests targeting this vulnerability. This means security teams must treat the vector database as a critical attack surface, not just a storage bucket.

Market Adoption and Future Trends
The adoption of RAG is accelerating rapidly across sectors. By late 2024, 81% of government agencies and 68% of financial institutions had implemented RAG for document-intensive applications, according to the GSA TechStat report and Deloitte’s 2025 Banking AI report, respectively. The market is projected to reach $14.3 billion by 2027, growing at a compound annual rate of 42.7%, per IDC forecasts.
We are now seeing the emergence of "Agentic RAG," pioneered by Microsoft’s AutoGen in February 2025. In this architecture, multiple AI agents collaborate to refine queries and validate retrieved information, reducing error rates by 29%. Additionally, multimodal RAG is on the horizon, integrating text, images, and video embeddings. OpenAI’s upcoming GPT-5 is expected to feature native multimodal RAG support, further blurring the lines between different data types.
Regulatory landscapes are also catching up. The EU AI Act’s December 2024 guidelines require RAG systems to disclose source provenance for high-risk applications. This means transparency is no longer optional; users must know where the information came from. Dr. Andrew Ng, founder of DeepLearning.AI, summarized the current state best: "RAG is the single most effective technique for reducing hallucinations in production LLM systems today."
Best Practices for Deployment
If you are planning to deploy RAG, start with your data maturity. Organizations with structured knowledge bases achieve 3.2x higher RAG effectiveness than those using unstructured data, according to MIT Sloan Management Review. Clean, well-organized data is half the battle.
- Optimize Chunk Size: Stick to 256-512 tokens with a 15-20% overlap to maintain context continuity.
- Use Hybrid Search: Combine keyword and vector search to catch exact matches that pure semantic search might miss.
- Implement Reranking: Use a dedicated reranker model to filter the top retrieved results before sending them to the LLM.
- Monitor Latency: Aim for sub-second retrieval times. Use caching for frequent queries and consider NVIDIA’s RAG-as-a-Service on DGX Cloud for enterprise-grade performance with 99.95% uptime SLA.
- Secure Your Knowledge Base: Treat your vector database with the same security rigor as your primary database to prevent retrieval poisoning.
What is the main benefit of using RAG over standard LLMs?
The primary benefit is significantly reduced hallucination. Standard LLMs rely on static training data, which can lead to fabricated answers. RAG grounds responses in verified, external sources, improving accuracy and trustworthiness, especially for time-sensitive or proprietary information.
Is RAG more expensive than fine-tuning?
No, RAG is generally much cheaper. Fine-tuning can cost over $50,000 per iteration due to compute requirements. RAG typically costs only 5-8% of that amount because it doesn't require retraining the model, only querying external data.
What are the common challenges with RAG implementation?
Common challenges include retrieval drift (irrelevant documents being fetched), context overload (too much information confusing the LLM), increased latency (slower response times), and security risks like retrieval poisoning where malicious actors corrupt the knowledge base.
Which vector databases are best for RAG?
Popular choices include Pinecone, Weaviate, and AWS OpenSearch. Pinecone is known for handling massive scale (up to 1.2 billion vectors per cluster), while Weaviate offers robust open-source capabilities. The choice often depends on existing cloud infrastructure and specific latency requirements.
Does RAG work well with non-English languages?
Performance varies. While English retrieval accuracy is high (around 89%), lower-resource languages like Swahili may see accuracy drop to around 58%. Using multilingual embedding models like Cohere's Embed Multilingual v3.0 can help mitigate this gap.
- Jun, 7 2026
- Collin Pace
- 0
- Permalink
- Tags:
- Retrieval-Augmented Generation
- RAG architecture
- LLM hallucination reduction
- vector databases
- enterprise AI grounding
Written by Collin Pace
View all posts by: Collin Pace