Tag: LLM scaling policies
Autoscaling Large Language Model Services: How to Balance Cost, Latency, and Performance
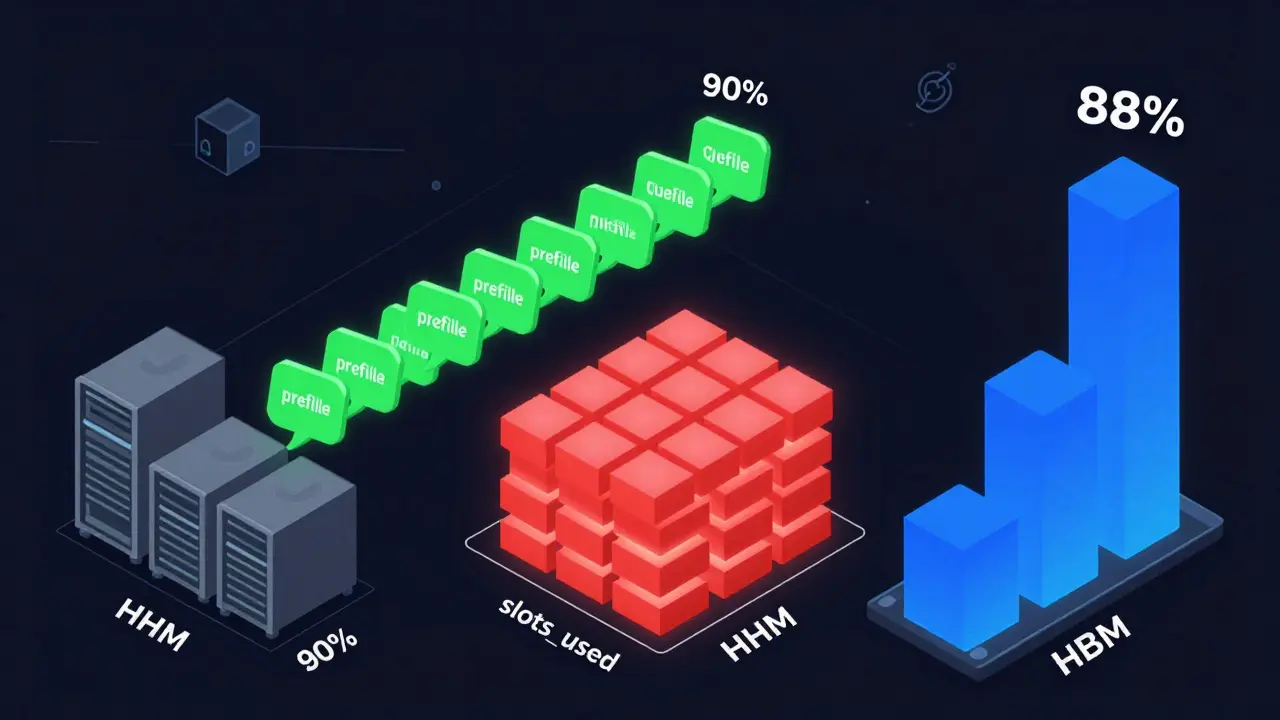
Learn how to autoscale LLM services effectively using the right signals-prefill queue size, slots_used, and HBM usage-to cut costs by up to 60% without sacrificing latency. Avoid common pitfalls and choose the right strategy for your workload.
- Aug 6, 2025
- Collin Pace
- 10
- Permalink