Traffic Shaping and A/B Testing for Large Language Model Releases: A Practical Guide
Rolling out a new version of a large language model (LLM) is not like updating a standard web app. You cannot simply flip a switch and hope for the best. If your new model hallucinates financial advice or struggles with complex reasoning, the damage happens instantly. That is why traffic shaping and rigorous A/B testing have become the backbone of modern LLMOps (Large Language Model Operations) strategies. These techniques allow you to control exactly who sees the new model, how much data it processes, and whether it performs better than its predecessor before you expose your entire user base to it.
In 2026, deploying an LLM without these safeguards is considered negligent in enterprise environments. The probabilistic nature of these models means that small changes in weights or prompts can lead to wildly different outputs. Traditional binary deployments-where you replace Version A with Version B overnight-are obsolete. Instead, successful teams use gradual exposure, real-time monitoring, and semantic routing to mitigate risk while gathering meaningful performance data.
Why Standard Deployment Fails for LLMs
Traditional software follows deterministic rules. If input X goes into function Y, output Z always comes out. LLMs do not work this way. They are probabilistic engines. This fundamental difference breaks traditional CI/CD pipelines when applied directly to model releases.
Consider a customer service bot. In a traditional app, if a button stops working, users see an error message. In an LLM application, if the new model version starts providing slightly inaccurate answers, users might not complain immediately. They just trust the wrong information. By the time you realize there is a regression, thousands of users may have already acted on bad advice.
This is where canary releases (a deployment strategy where a new version is released to a small subset of users first) become essential. Instead of sending 100% of traffic to the new model, you start with 1% or even 0.1%. This allows you to detect issues like increased latency, higher token costs, or subtle drops in accuracy before they impact your core business metrics.
According to industry analysis from Gartner, enterprises that skip proper traffic shaping face a significantly higher risk of deployment failures due to undetected model degradation. The goal is not just to launch faster, but to launch safely.
The Mechanics of Traffic Shaping
Traffic shaping is more than just splitting requests evenly between two servers. It involves intelligent routing decisions based on context, complexity, and user segmentation. Modern API gateways (software components that act as a reverse proxy to accept API requests) have evolved to handle these nuances.
Here is how effective traffic shaping works in practice:
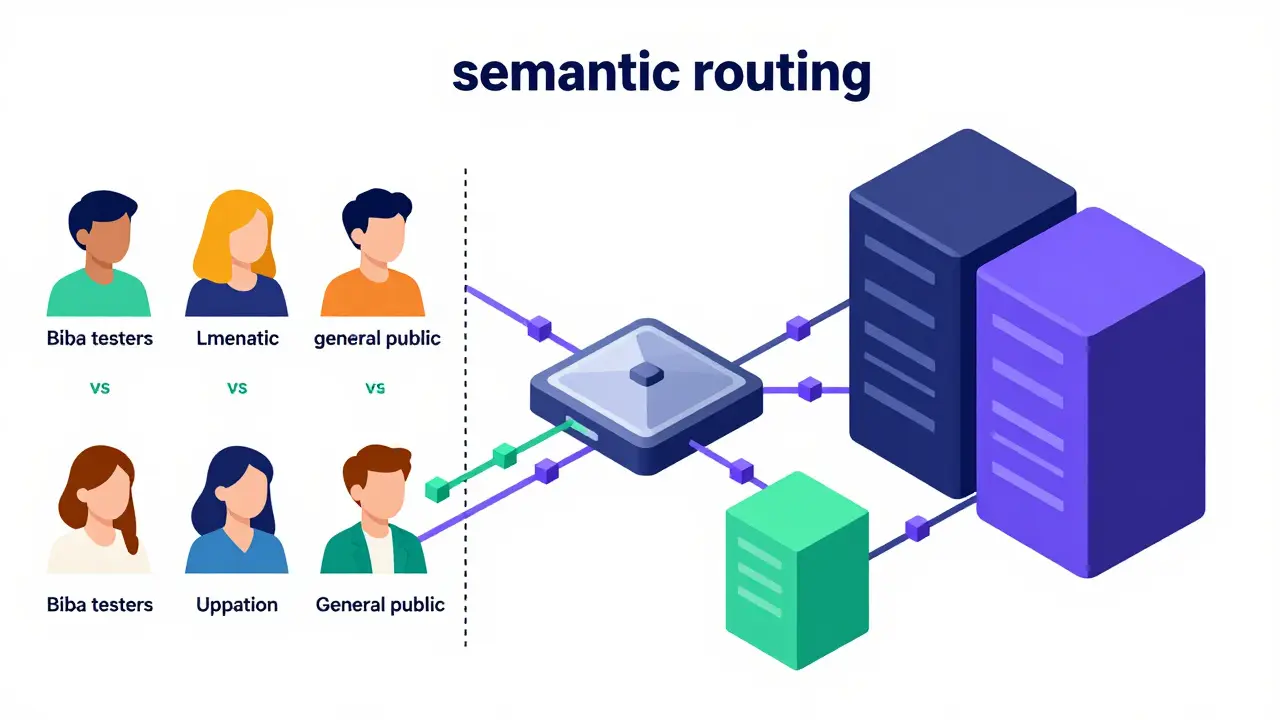
- Semantic Routing: Not all queries are created equal. Simple factual questions can be handled by smaller, cheaper models. Complex reasoning tasks require larger, more powerful variants. Your gateway analyzes the prompt content and routes it accordingly. This optimizes both cost and performance.
- User Segmentation: You might want to test a new model only on beta testers or internal employees first. Traffic shaping allows you to route specific user IDs or groups to the new variant while keeping the general public on the stable version.
- Complexity-Based Load Balancing: During peak hours, you might automatically route less critical requests to a lighter model to preserve resources for high-priority transactions.
Tools like Kong Gateway and specialized LLMOps platforms implement these algorithms dynamically. They act as adaptive traffic lights, adjusting flow in real-time based on current system health and request characteristics. This level of granularity was unnecessary for stateless APIs but is critical for managing the variable compute demands of LLM inference.
Designing Effective A/B Tests for Models
A/B testing in LLMs is notoriously difficult because "quality" is subjective. Unlike conversion rates in e-commerce, measuring the helpfulness of a text response requires careful metric design. You need a mix of automated and human evaluation methods.
Start by defining clear success criteria before you begin the test. Common metrics include:
- Latency: Time to first token (TTFT) and total generation time. For interactive applications, staying under 2 seconds is often a hard requirement.
- Cost Efficiency: Cost per thousand tokens. Newer models might be smarter but also more expensive. You need to know if the quality gain justifies the price hike.
- Accuracy: Measured against a gold-standard dataset of known correct answers. Automated scoring using a judge LLM can provide quick feedback, but it has its own biases.
- Safety Compliance: Rate of refusal for harmful prompts and adherence to content policies. This is non-negotiable in regulated industries.
A practical approach is to run a shadow test first. In this setup, the new model processes live traffic alongside the production model, but its responses are discarded. This lets you measure latency and cost impacts without risking user experience. Once you are confident in the technical stability, you move to active A/B testing where a percentage of users receive the new model's output.
Remember that statistical significance takes time. Do not rush to full rollout after one day of testing. Monitor trends over several days to account for daily usage patterns and seasonal variations in query types.
Infrastructure Requirements and Tools
Implementing robust traffic shaping requires a solid infrastructure foundation. You cannot rely on basic load balancers alone. You need systems capable of handling stateful conversations and real-time analytics.
| Approach | Implementation Effort | Cost Estimate (Monthly) | Best For |
|---|---|---|---|
| Custom Kubernetes Operators | High (3-6 months engineering) | Variable (Compute + Dev Time) | Large tech companies with dedicated platform teams |
| Commercial LLMOps Platforms (e.g., NeuralTrust) | Medium (Integration focused) | $15,000 - $25,000+ | Enterprises needing compliance and advanced features |
| Cloud-Native Solutions (AWS SageMaker, Vertex AI) | Low-Medium | $8,000 - $20,000 (Usage-based) | Teams already invested in a specific cloud ecosystem |
| Open Source Gateways (Kong, BentoML) | Medium | Low (Hosting costs only) | Startups and cost-conscious teams with DevOps expertise |
Key infrastructure capabilities you must ensure include:
- Real-Time Monitoring: Track over 50 distinct performance indicators. Alerts should trigger if key metrics deviate by more than 5% from baseline.
- Session Stickiness: Conversational AI requires maintaining context. If a user starts a chat with Model A, they should continue with Model A unless explicitly switched. Mixing models mid-conversation leads to disjointed experiences.
- Encryption and Security: Use end-to-end TLS 1.3 encryption for all traffic. Prevent model leakage during testing phases by strictly controlling access to new model endpoints.
NVIDIA’s guidelines for enterprise LLM operations emphasize that systems must support at least 99.95% uptime during transitions and handle traffic spikes of up to 300% above baseline without degradation. This resilience is crucial when running parallel instances of old and new models.
Risks, Costs, and Mitigation Strategies
There is no free lunch in LLMOps. Running multiple model versions simultaneously increases your infrastructure costs by 15-25% during transition periods. You are paying for compute resources that are essentially idle while waiting for test results.
To mitigate these costs:
- Use Shadow Testing Wisely: Only process a sample of traffic in shadow mode rather than every single request. Stratified sampling ensures you still get representative data without the full compute load.
- Automate Rollbacks: Define clear failure thresholds. If the new model’s latency exceeds 2 seconds or safety violations spike, the system should automatically revert traffic to the previous version within seconds. Manual intervention is too slow.
- Leverage Multi-Armed Bandit Algorithms: Instead of static 50/50 splits, use algorithms that automatically shift more traffic to the better-performing variant in real-time. This reduces the window of suboptimal performance.
Security is another major concern. During A/B testing, you are exposing new model weights to live data. Ensure that your testing environment is isolated and that sensitive user data is anonymized before being fed to the new model for processing. Regulatory frameworks like the EU AI Act increasingly mandate rigorous risk management procedures for high-impact AI systems, making documented, gradual deployment strategies a legal necessity rather than just a best practice.
Future Trends in Model Deployment
The field of LLMOps is evolving rapidly. By 2026, we are seeing a shift from manual configuration to automated, self-optimizing systems. Cloud providers like Google Cloud and AWS are introducing features that automatically detect statistical significance in A/B tests and adjust traffic allocation without human intervention.
Look out for these emerging trends:
- Adaptive Learning Routers: Systems that continuously analyze traffic patterns and self-optimize routing decisions based on workload distribution and latency fluctuations.
- Integrated Evaluation Frameworks: Tighter coupling between traffic management and model evaluation tools. Future systems will likely pause rollouts automatically if real-time evaluation scores drop below acceptable levels.
- Cost-Aware Shaping: Algorithms that balance quality and cost dynamically. For example, routing urgent, high-value queries to premium models while deferring low-priority batch jobs to cheaper, slower variants.
While the technology is improving, the core principle remains unchanged: never trust a model until you have tested it in the wild. The complexity of LLMs demands a cautious, data-driven approach to deployment. Investing in robust traffic shaping and A/B testing infrastructure today will save you from catastrophic failures and costly rollbacks tomorrow.
What is the difference between traffic shaping and load balancing for LLMs?
Traditional load balancing distributes requests evenly across servers to prevent overload. Traffic shaping for LLMs goes further by analyzing the content of the request (semantic routing), user identity, and model performance metrics to make intelligent decisions about which model instance handles which request. It optimizes for quality, cost, and safety, not just server capacity.
How much traffic should I send to a new LLM version initially?
Start small. Industry best practices suggest beginning with 1% to 5% of total traffic for a canary release. Monitor key metrics closely for at least 24-48 hours. If no anomalies are detected, gradually increase the percentage in steps (e.g., 10%, 25%, 50%) before moving to full rollout.
Is A/B testing necessary for every LLM update?
For minor prompt tweaks or parameter adjustments, shadow testing might suffice. However, for any change to the model weights, architecture, or significant prompt restructuring, active A/B testing is strongly recommended. The probabilistic nature of LLMs means even small changes can have unpredictable effects on output quality and safety.
What are the biggest challenges in implementing LLM traffic shaping?
The main challenges include high infrastructure costs due to running parallel models, the difficulty of defining objective quality metrics for subjective outputs, and the complexity of managing stateful conversations across different model versions. Additionally, finding skilled engineers who understand both distributed systems and ML operations is difficult.
Can open-source tools handle enterprise-grade LLM traffic shaping?
Yes, tools like Kong Gateway and BentoML offer robust capabilities for traffic shaping and can be customized for enterprise needs. However, they require significant engineering effort to set up and maintain compared to commercial LLMOps platforms. Open-source solutions are ideal for teams with strong DevOps expertise and budget constraints.
- Jul, 1 2026
- Collin Pace
- 0
- Permalink
Written by Collin Pace
View all posts by: Collin Pace