Foundational Technologies Behind Generative AI: Transformers, Diffusion Models, and GANs Explained
Every time you ask an AI to write an email, generate a photorealistic image of a cat in space, or create a video clip from text, one of three specific technologies is doing the heavy lifting. These are not magic tricks; they are mathematical frameworks that have evolved over the last decade. To understand where artificial intelligence is heading, you need to look under the hood at the three foundational pillars: Transformers, Diffusion Models, and Generative Adversarial Networks (GANs). Each has distinct strengths, weaknesses, and ideal use cases. By late 2025, these three architectures power roughly 92% of all commercial generative AI applications, but they do not work the same way.
The Transformer Architecture: Mastering Sequence and Language
If you have used ChatGPT, Gemini, or any modern language model, you are interacting with a Transformer. Introduced in the seminal 2017 paper 'Attention is All You Need' by researchers at Google Brain, this architecture revolutionized how machines process information. Before Transformers, models read data sequentially, word by word, like a human reading a book. This was slow and limited their ability to connect distant ideas within a long text.
Transformers changed the game with a mechanism called self-attention. Instead of reading linearly, the model looks at the entire sequence of words simultaneously. It calculates the relationship between every word and every other word in the sentence. This allows it to understand context deeply-for example, knowing that "bank" refers to a river edge in one sentence and a financial institution in another, based on the surrounding words.
| Attribute | Value / Detail |
|---|---|
| Core Mechanism | Self-Attention (parallel processing of sequences) |
| Dominant Use Case | Natural Language Processing (NLP), Text Generation |
| Training Cost (Example) | GPT-4 class models require ~50 GWh electricity per cycle |
| Market Share (2024) | 58% of generative AI implementations |
| Primary Limitation | Quadratic complexity with sequence length; high memory usage |
The downside? Transformers are computationally expensive. Training a large model like GPT-4 requires thousands of GPUs and consumes massive amounts of energy-approximately 50 gigawatt-hours for a single training run, according to MIT Technology Review’s 2024 analysis. However, for tasks involving logic, language, code, and structured data, nothing else comes close. As of 2026, they remain the undisputed kings of text-based generation.
Diffusion Models: The King of Image Quality
While Transformers dominate text, Diffusion Models have taken over image generation. You likely know them from tools like Midjourney, DALL-E 3, and Stable Diffusion. The concept traces back to physics principles described in a 2015 paper by Sohl-Dickstein et al., but practical, high-quality implementations only emerged around 2020.
How does diffusion work? Imagine taking a clear photograph and slowly adding static noise until it becomes pure white chaos. That is the forward process. A diffusion model learns to reverse this process. It starts with random noise and gradually removes the static, step by step, guided by your text prompt, until a coherent image emerges. Early versions required 1,000 steps to clean up the noise, which was slow. Modern variants like Stable Diffusion 3 (released in 2024) have optimized this to around 20-50 steps without sacrificing quality.
The main advantage of diffusion models is stability and diversity. Unlike older methods, they rarely get stuck producing the same few images (a problem known as mode collapse). They also produce incredibly sharp, detailed results. In benchmarks from Sapien.io in 2024, Stable Diffusion XL achieved a Fréchet Inception Distance (FID) score of 1.68, significantly better than competing architectures. Lower FID scores indicate higher similarity to real human-created images.
However, speed remains a challenge. Generating a single high-resolution image can take 12-15 seconds on standard hardware. For real-time applications like video games or live video filters, this latency is unacceptable. Developers often use techniques like knowledge distillation to speed up inference, though this may result in a slight drop in visual fidelity.

GANs: The Speed Demon with Stability Issues
Generative Adversarial Networks (GANs), pioneered by Ian Goodfellow in 2014, were the first major breakthrough in generative AI. Despite being overshadowed by diffusion models in recent years, GANs still hold niche importance, particularly in real-time video and gaming.
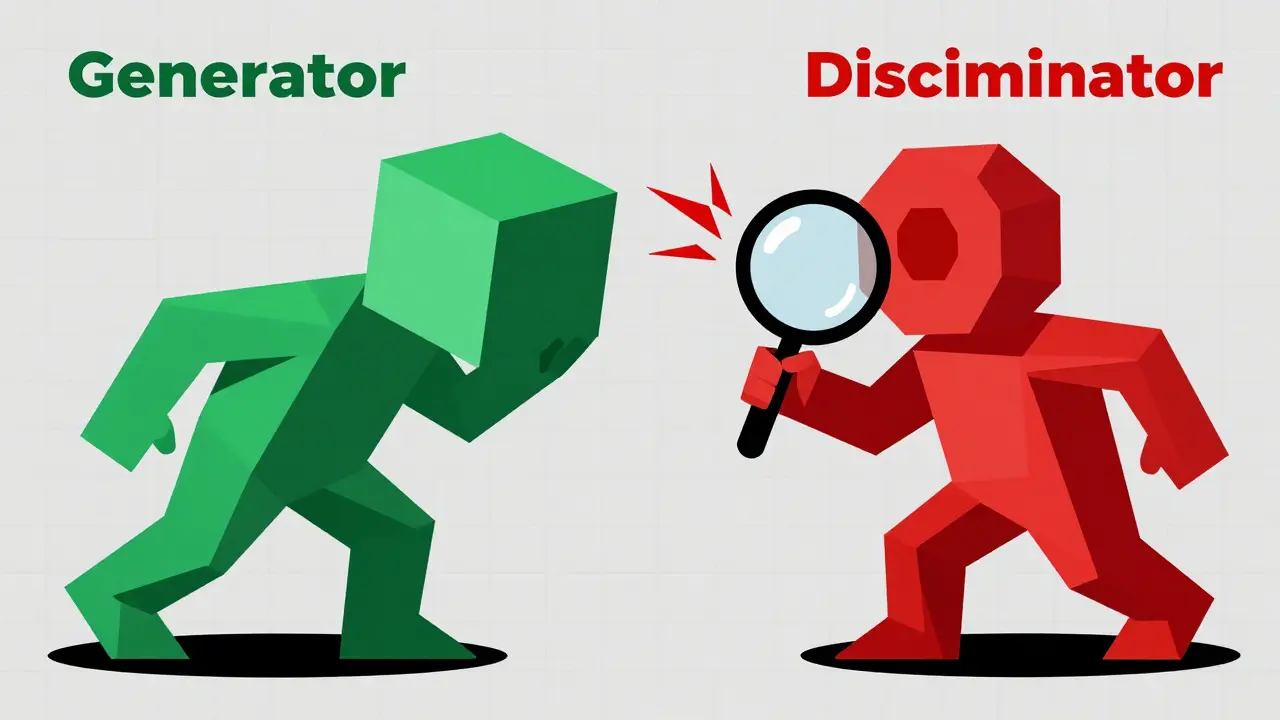
A GAN consists of two neural networks playing a zero-sum game against each other:
- The Generator: Creates fake data (images, audio) from random noise.
- The Discriminator: Tries to distinguish between real data and the generator's fakes.
As the discriminator gets better at spotting fakes, the generator is forced to improve its craft to fool it. This adversarial training loop produces highly realistic outputs very quickly. NVIDIA’s StyleGAN3, for instance, can generate a 1024x1024 resolution image in just 0.8 seconds. Compare that to the 12+ seconds for diffusion models, and you see why GANs are still used for real-time applications like NVIDIA’s Maxine platform for video enhancement.
But GANs are notoriously difficult to train. They suffer from mode collapse, where the generator finds one or two images that consistently fool the discriminator and stops creating anything new. According to Turing IT Labs’ 2023 deep dive, mode collapse affects 63% of standard GAN implementations. This instability led many developers to abandon GANs for diffusion models when image quality became more important than generation speed.
Comparing the Three: Which Should You Choose?
Selecting the right architecture depends entirely on your end goal. There is no single "best" model. Here is how they stack up in key performance metrics:
| Metric | Transformers | Diffusion Models | GANs |
|---|---|---|---|
| Best For | Text, Code, Logic, Multimodal Reasoning | High-Fidelity Image Synthesis | Real-Time Video, Fast Image Gen |
| Generation Speed | Fast (for text tokens) | Slow (seconds per image) | Very Fast (milliseconds) |
| Training Stability | High | High | Low (prone to mode collapse) |
| Data Requirements | Massive (billions of tokens) | Very High (2.3B pairs for SD) | Moderate (450M pairs sufficient) |
| Compute Cost | Extremely High | High | Moderate |
If you are building a customer service bot or a coding assistant, you need a Transformer. If you are creating marketing assets or artistic illustrations, a Diffusion Model is your best bet due to superior detail and lack of artifacts. If you are developing a video game character face or a real-time deepfake filter, a GAN might still be the most efficient choice despite its training headaches.
The Future: Hybrid Architectures and Convergence
The lines between these three technologies are blurring. By late 2024 and into 2025, we saw the rise of hybrid models that combine the strengths of each. Google’s Gemini 1.5 integrated diffusion techniques with Transformer attention mechanisms, reducing image generation time by 65% while maintaining high quality. Similarly, Stability AI’s SD3 uses a hybrid diffusion-transformer approach to cut inference steps down to 20.
NVIDIA also released GANformer2 in November 2024, which combines the efficiency of GANs with the attention mechanisms of Transformers. This allowed for 25 FPS video generation with significantly less mode collapse. Industry experts predict that by 2027, the distinction between these architectures will fade as hybrid approaches become the standard.
Regulatory changes are also shaping adoption. The EU AI Act’s implementation in 2024 requires transparency about which architecture generated content. This has pushed enterprises to document their tech stacks carefully, with 73% of European deployments now tracking architectural lineage for compliance.
What is the main difference between Transformers and Diffusion Models?
Transformers primarily handle sequential data like text and code using self-attention mechanisms, making them ideal for NLP. Diffusion Models handle unstructured data like images by gradually removing noise from random static, making them superior for high-fidelity image generation.
Are GANs obsolete compared to Diffusion Models?
Not entirely. While Diffusion Models offer better image quality and stability, GANs are significantly faster at generating images. For real-time applications like video games or live video filters where latency must be under 100ms, GANs remain the preferred choice.
Which AI architecture is most energy-intensive?
Transformers are generally the most energy-intensive. Training large language models like GPT-4 can consume approximately 50 gigawatt-hours of electricity per cycle, which exceeds the lifetime emissions of several average households.
What is mode collapse in GANs?
Mode collapse occurs when the generator in a GAN finds a single output (or a few outputs) that consistently fools the discriminator. Instead of learning to create diverse data, it repeats the same successful fake, resulting in a lack of variety in generated content.
Will hybrid models replace standalone architectures?
Yes, industry trends suggest convergence. Models like Google’s Gemini and Stability AI’s SD3 already combine Transformer and Diffusion techniques. Experts predict that by 2027, hybrid architectures will dominate as they balance speed, quality, and versatility.
- May, 29 2026
- Collin Pace
- 9
- Permalink
- Tags:
- Generative AI architectures
- Transformers vs Diffusion
- GANs explained
- AI model comparison
- generative AI foundations
Written by Collin Pace
View all posts by: Collin Pace