Category: AI Infrastructure
Transformer Efficiency Tricks: KV Caching and Continuous Batching in LLM Serving

KV caching and continuous batching are essential for efficient LLM serving. They reduce compute by 90% and boost throughput 3.8x, making long-context responses feasible. Without them, deploying LLMs at scale is prohibitively expensive.
- Mar 22, 2026
- Collin Pace
- 3
- Permalink
When to Compress vs When to Switch Models in Large Language Model Systems

Learn when to compress a large language model versus switching to a smaller one. Discover practical trade-offs in cost, accuracy, and hardware that shape real-world AI deployments.
- Mar 2, 2026
- Collin Pace
- 9
- Permalink
Cost Management for Large Language Models: Pricing Models and Token Budgets
Learn how to control LLM costs with token budgets, pricing models, and optimization tactics. Reduce spending by 30-50% without sacrificing performance using real-world strategies from 2026’s leading practices.
- Jan 23, 2026
- Collin Pace
- 9
- Permalink
Confidential Computing for Privacy-Preserving LLM Inference: How Secure AI Works Today

Confidential computing enables secure LLM inference by protecting data and model weights inside hardware-secured enclaves. Learn how AWS, Azure, and Google implement it, the real-world trade-offs, and why regulated industries are adopting it now.
- Jan 21, 2026
- Collin Pace
- 8
- Permalink
Model Compression Economics: How Quantization and Distillation Cut LLM Costs by 90%

Learn how quantization and knowledge distillation slash LLM inference costs by up to 95%, making powerful AI affordable for small teams and edge devices. Real-world results, tools, and best practices.
- Dec 29, 2025
- Collin Pace
- 6
- Permalink
Autoscaling Large Language Model Services: How to Balance Cost, Latency, and Performance
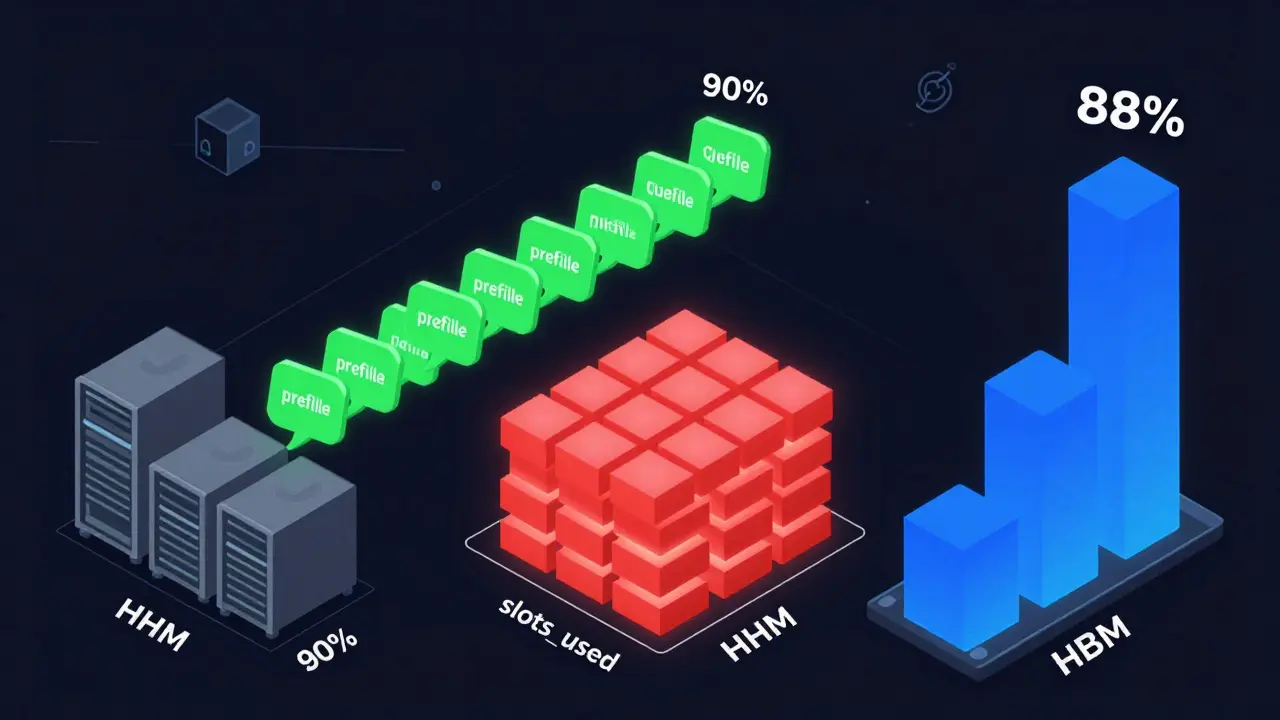
Learn how to autoscale LLM services effectively using the right signals-prefill queue size, slots_used, and HBM usage-to cut costs by up to 60% without sacrificing latency. Avoid common pitfalls and choose the right strategy for your workload.
- Aug 6, 2025
- Collin Pace
- 10
- Permalink