Archive: 2026/05 - Page 3
How to Measure ROI of LLM Agents in Enterprise Workflows: A Practical Guide

Learn how to accurately measure the ROI of Large Language Model agents in enterprise workflows. Discover key metrics, calculation formulas, and strategic frameworks to justify AI investments.
- May 7, 2026
- Collin Pace
- 0
- Permalink
RAG with Vector Databases: Embeddings, HNSW Indexing, and Filters
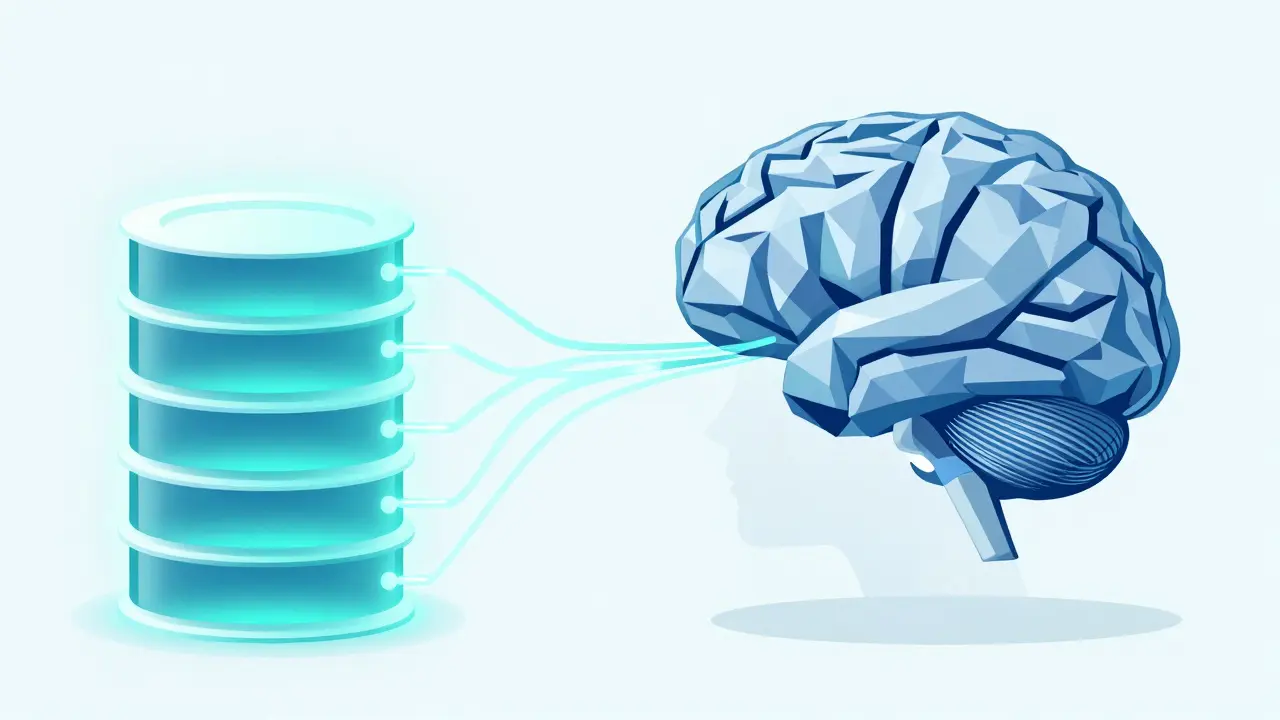
Learn how Retrieval-Augmented Generation (RAG) uses vector databases, embeddings, and HNSW indexing to reduce AI hallucinations and improve accuracy with real-time data.
- May 6, 2026
- Collin Pace
- 0
- Permalink
Llama vs Mistral vs Qwen vs DeepSeek: Choosing the Best Open-Source LLM in 2026

Compare Llama 4, Mistral Large, Qwen 3, and DeepSeek R1 for 2026. Analyze licensing, costs, and performance to choose the best open-source LLM for your business.
- May 5, 2026
- Collin Pace
- 0
- Permalink
How to Choose the Right Vibe Coding Platform for Your Team in 2026

Discover how to choose the right vibe coding platform for your team in 2026. We compare top tools like Replit, Windsurf, and Noca based on price, security, and team fit to boost developer productivity.
- May 4, 2026
- Collin Pace
- 0
- Permalink
How LLM Attention Works: Key, Query, and Value Projections Explained

Explore how Key, Query, and Value matrices drive attention in LLMs. Understand their roles, math, and impact on AI performance with clear explanations and practical insights.
- May 3, 2026
- Collin Pace
- 0
- Permalink
Building a Vibe Coding Center of Excellence: Charter, Staffing, and Goals

Learn how to build a Vibe Coding Center of Excellence (CoE) in 2026. Covers charter creation, staffing strategies, and goal setting to balance AI-driven speed with governance.
- May 2, 2026
- Collin Pace
- 0
- Permalink
Sliding Windows and Memory Tokens: Extending LLM Attention

Explore how Sliding Window Attention and Memory Tokens extend Large Language Model capabilities. Learn about transformer design optimizations that balance computational efficiency with long-context understanding.
- May 1, 2026
- Collin Pace
- 0
- Permalink